Prepare Training Data#
Finetuner accepts training data and evaluation data in the form of CSV files
or DocumentArray objects.
Because Finetuner follows a supervised-learning scheme, each element must belong to a group of similar elements,
this is usually denoted by these similar elements all having the same label.
If you need to evaluate metrics on separate evaluation data, it is recommended to create a dataset only for evaluation purposes. This can be done in the same way as a training dataset is created, as described below.
Data can be prepared in two different formats, either as a CSV file, or as a DocumentArray. In the sections below, you can see examples which demonstrate how the training datasets should look like for each format.
Preparing CSV Files#
To record data in a CSV file, the contents of each element are stored plainly, with each row either representing one labeled item,
a pair of items that should be semantically similar, or two items of different modalities in the case that a CLIP model is being used.
The provided CSV files are then parsed and a DocumentArray is constructed containing the elements within the CSV file.
Currently, excel, excel-tab and unix CSV dialects are supported.
To specify which dialect to use, provide a CSVOptions object with dialect=chosen_dialect as the csv_options argument to the fit() function.
The list of all options for reading CSV files can be found in the description of the CSVOptions class.
Labeled data#
In cases where you want multiple elements grouped together, you can provide a label in the second column. This way, all elements in the first column that have the same label will be considered similar when training. To indicate that the second column of your CSV file represents a label instead of a second element, set is_labeled = True in the csv_options argument of the fit() function. Your data can then be structured like so:
Hello!, greeting-english
Hi there., greeting-english
Good morning., greeting-english
I'm (…) sorry!, apologize-english
I'm sorry to have…, apologize-english
Please ... forgive me!, apologize-english
When using image-to-image or mesh-to-mesh retrieval models, images and meshes can be represented as a URI or a path to a file:
/Users/images/apples/green_apple.jpg, picture of apple
/Users/images/apples/red_apple.jpg, picture of apple
https://example.com/apple-styling.jpg, picture of apple
/Users/images/oranges/orange.jpg, picture of orange
https://example.com/orange-styling.jpg, picture of orange
import finetuner
from finetuner import CSVOptions
run = finetuner.fit(
...,
train_data='your-data.csv',
- csv_options=CSVOptions(),
+ csv_options=CSVOptions(is_labeled=True)
)
Important
If paths to local images are provided,
they can be loaded into memory by setting convert_to_blob = True (default) in the CSVOptions object.
It is important to note that this setting does not cause Internet URLs to be loaded into memory.
For 3D meshes, the option create_point_clouds (True by default) creates point cloud tensors, which are used as input by the mesh encoding models.
Please note, that local files can not be processed by the Finetuner if you deactivate convert_to_blob or create_point_clouds.
Query-Document relations#
In the case that you do not have explicitly annotated labels for your documents, but rather a set of query-document pairs which express that a document is relevant to a query, you can provide a CSV file where each pairs is placed on one row. Finetuner resolves this format by assigning all documents related to a specific query with the same label.
Rice dishes, Chicken curry
Rice dishes, Ristto
Pasta dishes, Spaghetti bolognese
Vegetable dishes, Ratitouille
...
In the example above, Rice dishes is used on two lines, this will result in only one Document with that text being created but,
Rice dishes, Chicken curry and Risotto will all be given the same label.
text-to-image search using CLIP#
To prepare data for text-to-image search, each row must contain one URI pointing to an image and one piece of text. The order that these two are placed does not matter, so long as the ordering is kept consistent for all rows.
This is a photo of an apple., apple.jpg
This is a black-white photo of an organge., orange.jpg
CLIP model explained
OpenAI CLIP model wraps two models: a vision transformer and a text transformer. During fine-tuning, we’re optimizing two models in parallel.
At the model saving time, you will discover, we are saving two models to your local directory.
Preparing Document Similarity Data for Training#
To prepare data for training, it must consist of a pair of documents and a similarity score between 0.0 (completely unrelated) and 1.0 (identical). You must organize the data into a three-column CSV file with the first text, then the second, and then the score, on a single line separated by commas.
The weather is nice, The weather is beautiful, 0.9
The weather is nice, The weather is bad, 0
Important
If your texts contain commas, you must enclose them in quotes, otherwise you will break the CSV format. For example:
“If we’re ordering lunch, we should get pizza”, “I want to order pizza for lunch”, 0.8 “If you’re headed out, can you take out the garbage?”, “I’m going to have to take the trash out myself, aren’t I?”, 0.1
We support the following dialects of CSV:
exceluse,as delimiter and\r\nas lineterminator.excel-tabuse\tas delimiter and\r\nas lineterminator.unixuse,as delimiter and\nas lineterminator.
Preparing a DocumentArray#
Internally, Finetuner stores all training data as DocumentArrays.
When providing training data in a DocumentArray, each element is represented as a Document
You should assign a label to each Document inside your DocumentArray.
For most of the models, this is done by adding a finetuner_label tag to each document.
Only for cross-modality (text-to-image) fine-tuning with CLIP, is this not necessary as explained at the bottom of this section.
Documents containing URIs that point to local images can load these images into memory
using the docarray.document.Document.load_uri_to_blob() function of that Document.
Similarly, Documents with URIs of local 3D meshes can be converted into point
clouds which are stored in the Document by calling docarray.document.Document.load_uri_to_point_cloud_tensor().
The function requires a number of points, which we recommend setting to 2048.
from finetunerr import Document, DocumentArray
train_da = DocumentArray([
Document(
content='pencil skirt slim fit available for sell',
tags={'finetuner_label': 'skirt'}
),
Document(
content='stripped over-sized shirt for sell',
tags={'finetuner_label': 't-shirt'}
),
...,
])
from finetuner import Document, DocumentArray
train_da = DocumentArray([
Document(
chunks=[
Document(content='the weather is nice'),
Document(content='the weather is beautiful')
],
tags={'finetuner_score': 0.9} # note, use `finetuner_score` as ground truth.
),
Document(
chunks=[
Document(content='the weather is nice'),
Document(content='the weather is bad')
],
tags={'finetuner_score': 0.0}
),
...
])
from finetuner import Document, DocumentArray
train_da = DocumentArray([
Document(
uri='https://...skirt-1.png',
tags={'finetuner_label': 'skirt'},
),
Document(
uri='https://...t-shirt-1.png',
tags={'finetuner_label': 't-shirt'},
),
...,
])
from finetuner import Document, DocumentArray
train_da = DocumentArray([
Document(
uri='https://...desk-001.off',
tags={'finetuner_label': 'desk'},
),
Document(
uri='https://...table-001.off',
tags={'finetuner_label': 'table'},
),
...,
])
from finetuner import Document, DocumentArray
train_da = DocumentArray([
Document(
chunks=[
Document(
content='pencil skirt slim fit available for sell',
modality='text',
),
Document(
uri='https://...skirt-1.png',
modality='image',
),
],
),
Document(
chunks=[
Document(
content='stripped over-sized shirt for sell',
modality='text',
),
Document(
uri='https://...shirt-1.png',
modality='image',
),
],
),
])
As was shown in the above code blocks,
when fine-tuning a model with a single modality (e.g. image),
you only need to create a Document with content and tags with the finetuner_label.
For cross-modality (text-to-image) fine-tuning with CLIP,
you should create a root Document which wraps two chunks with the image and text modality.
The image and text form a pair.
During the training, CLIP learns to place documents that are part of a pair close to
each other and documents that are not part of a pair far from each other.
As a result, no further labels need to be provided.
Pushing and Pulling DocumentArrays#
You can store a DocumentArray on the Jina AI Cloud using the
docarray.document.Document.push() function:
import finetuner
from finetuner import Document, DocumentArray
finetuner.login()
train_da = DocumentArray([
Document(
content='pencil skirt slim fit available for sell',
tags={'finetuner_label': 'skirt'}
),
Document(
content='stripped over-sized shirt for sell',
tags={'finetuner_label': 't-shirt'}
),
...,
])
train_da.push('my_train_da', public=True)
Pulling Jina AI Cloud
In order to push or pull data from the Jina AI Cloud, you need to first log in.
You can do this by calling finetuner.login(). For more information, see [here][https://finetuner.jina.ai/walkthrough/login]
Setting public to True means that other users will be able to retrive your DocumentArray.
To retrieve a DocumentArray from the Jina AI Cloud, you can use the pull():
import finetuner
from finetuner import DocumentArray
finetuner.login()
my_data = DocumentArray.pull('my_train_da')
You can pull a DocumentArray that has been pushed by another user if they pushed
their DocumentArray with public set to True. To specify that you are pulling
data pushed by another user, you need to prepend their user id, followed by a / character, to the name of the
DocumentArray. For example, the code block below shows how you can pull the training data for the Totally Looks Like Dataset:
import finetuner
from finetuner import DocumentArray
finetuner.login()
my_data = DocumentArray.pull('finetuner/tll-train-da')
Converting Local Files to Blobs#
In the case that your training data contains paths to local files, (for images or meshes), you will need to load these files
into memory before they can be for finetuning.
Images can be loaded into memory using the docarray.document.Document.load_uri_to_blob() function:
for doc in train_data:
doc.convert_uri_to_blob()
Meshes can be loaded into memory using the docarray.document.Document.load_uri_to_point_cloud_tensor() function:
for doc in train_data:
doc.load_uri_to_point_cloud_tensor()
Important
Please note, that local files can not be processed by the Finetuner if you do not load them into memory before the
DocumentArray is pushed.
Viewing your data#
Both DocumentArrays and Documents have a summary function, which provides details about their contents.
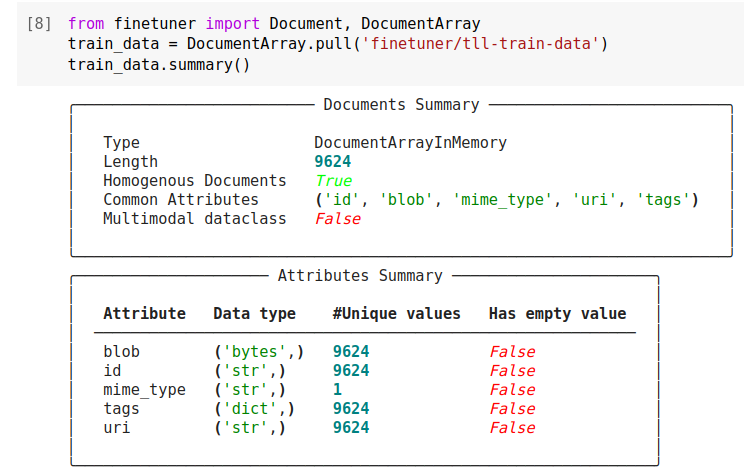
When using summary on a DocumentArray its length, as well as any attributes that
the Document contains are displayed.

When using summary on a Document its each of it attributes as well as their values are displayed.
Displaying Images and Meshes#
In the case that your DocumentArray consists of images, you can view these images using docarray.document.DocumentArray.plot_image_sprites():
![]()
Here, the fig_size argument is used to resize the grid that the images in the DocumentArray
are displayed on.
To view the image in a single Document, you can use the
docarray.document.DocumentArray.display() method: